
Wir haben die parallele Turbulenzsimulation auf verschiedenen Parallelrechnern implementiert und dabei einen Überblick über die Leistungsfähigkeit des Programms auf diesen Rechnerarchitekturen erhalten. Besonders interessant waren folgende Parallelrechner der Firmen Cray, IBM und Silicon Graphics:
CRAY T3D: 256 DEC Alpha Prozessoren mit je 64 MB Speicher und einer maximalen Rechenleistung von 150 MFlop/s (Installation am Konrad-Zuse-Zentrum für Informationstechnik in Berlin).
IBM SP-2: 58 Power2-Prozessoren mit je 256 MB und einer maximalen Rechenleistung von 267 MFlop/s. Zusätzlich 8 Power2 mit 128 MB und 133 MFlop/s (Deutsche Forschungsanstalt für Luft- und Raumfahrt in Köln-Porz).
SNI SC900/ SGI Power Challenge: 16 MIPS R8000 Prozessoren mit 8 GB gemeinsamem Speicher und einer Prozessorleistung von 300 MFlop/s (Regionales Rechenzentrum an der Universität zu Köln).
Alle drei Rechner unterstützen das SPMD (Single Program Multiple Data) Programmiermodell. Die Kommunikation erfolgt auf der Cray T3D über eine dreidimensionale Gittertopologie, auf der SP-2 über einen Kreuzschienenschalter, der direkte Schaltungen zwischen zwei beliebigen Prozessoren zuläßt und auf der SNI SC900 über einen gemeinsamen Datenbus mit 1,2 GB Bandbreite.
Die Portierung des Codes auf die oben beschriebenen Rechnersysteme
gestaltete sich aufgrund der Verwendung von MPI unkompliziert. Obwohl
das Shared-Memory-Konzept der SGI Power Challenge grundsätzlich nicht
für die Message-Passing-Programmierung entwickelt wurde, stellte sich
heraus, daß die Maschine gut für diese Art von Parallelisierung
geeignet ist.
Bei einem Vergleich der Laufzeiten ist zu
berücksichtigen, daß die Leistungsmessung auf der SGI im normalen
Benutzerbetrieb stattfand. Der Datenbus und die Prozessoren mußten also mit
vielen anderen Benutzern geteilt werden. Grundsätzlich anders
ist dies auf der Cray T3D. Hier
erhält man eine feste Anzahl Prozessoren zur exklusiven Nutzung
zugeteilt. Auch auf der SP-2 der DLR wurden für die Zeitmessung die Prozessoren und die
Kommunikation über den High Performance Switch in diesem dedizierten
Modus betrieben.
Die in der Tabelle ( ) dargestellten Zeiten beziehen
sich auf Simulationen mit einer Auflösung von
) dargestellten Zeiten beziehen
sich auf Simulationen mit einer Auflösung von 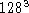 Gitterpunkten.
Mit Laufzeit pro Zeitschritt bezeichnen wir die Zeit in Sekunden, die
für einen Integrationsschritt benötigt wird. Ein Produktionslauf
benötigt bei dieser Auflösung typischerweise mehrere tausend
solcher Zeitschritte.
Der
Speed-up bezieht sich auf die Laufzeit auf einem Prozessor innerhalb
des gleichen Rechners.
Auf der Cray T3D konnte aus
Speicherplatzgründen das Programm nicht auf einem Prozessor
laufen. Aus diesem Grunde kann hierfür kein Speed-up angegeben
werden.
Gitterpunkten.
Mit Laufzeit pro Zeitschritt bezeichnen wir die Zeit in Sekunden, die
für einen Integrationsschritt benötigt wird. Ein Produktionslauf
benötigt bei dieser Auflösung typischerweise mehrere tausend
solcher Zeitschritte.
Der
Speed-up bezieht sich auf die Laufzeit auf einem Prozessor innerhalb
des gleichen Rechners.
Auf der Cray T3D konnte aus
Speicherplatzgründen das Programm nicht auf einem Prozessor
laufen. Aus diesem Grunde kann hierfür kein Speed-up angegeben
werden.
Das Programm skaliert auf allen drei Architekturen sehr gut. Dabei ist der superlineare Speed-up auf der IBM SP-2 auf eine effektivere Nutzung des Caches zurückzuführen, wenn die auf dem einzelnen Prozessor zu berechnenden Teilfelder kleiner werden. Die schnellste Laufzeit erreicht man auf 64 Prozessoren der SP-2 mit 0.58 Sekunden. Auf der T3D ist man auf 128 Prozessoren mit 0.93 Sekunden um das 1.6-fache langsamer und erhält in etwa die gleiche Leistung wie auf 32 Prozessoren der SP-2. Mit nur 8 Prozessoren benötigt die SGI zwar wesentlich länger (3.34 Sekunden), erreicht aber die höchste Rechenleistung pro Prozessor.